
比较一个变量在不同组中的分布是数据科学中的一个常见问题。当我们想要评估一项策略(用户体验功能、广告活动、药物等)的因果效应时,因果推断的黄金标准便是随机对照试验,也就是所谓的A /B测试。在实践中,我们为研究选择一个样本,并将其随机分为对照组(control group)和实验组(treatment group)比较两组之间的结果。随机化确保了两组之间的唯一差异,这样我们就可以将结果差异归因于实验效果。
因为是随机的所以两组个体不会完全的相同(identical)。但是有时候,它们在总体表现时甚至不是“相似”的(similar)。例如,我们可能在一个群体中有更多的男性,或者年长的人,等等。(我们通常称这些特征为协变量或控制变量)。当这种情况发生时,就不能再确定结果的差异只是由于实验得来的。因此,随机化后,检查所有观察变量是否在组间平衡,是否没有系统差异是非常重要的。
在这篇文章中,我们将看到比较两个(或更多)分布的不同方法,并评估它们差异的量级和重要性。我们将考虑两种不同的方法,可视化和统计。这两种方法可以为我们的提供直觉和严谨的数值来快速评估和探索差异,但是需要注意的是,这些方法很难区分这些差异是系统性的还是由于噪声造成的。
假设我们需要对一组人进行实验并且已经将他们随机分为实验组和对照组。我们希望它们尽可能具有可比性,以便将两组之间的任何差异仅归因于实验效果。我们还将实验组分为不同的组,以检验不同实验方法的效果(例如,同一种药物的轻微变化)。
对于这个例子,我模拟了1000个人的数据集,我们观察他们的一组特征。我从src导入了数据生成进程dgp_rnd_assignment()。DGP和src.utils中的一些绘图函数和库。
from src.utils import *
from src.dgp import dgp_rnd_assignment
df = dgp_rnd_assignment().generate_data()
df.head()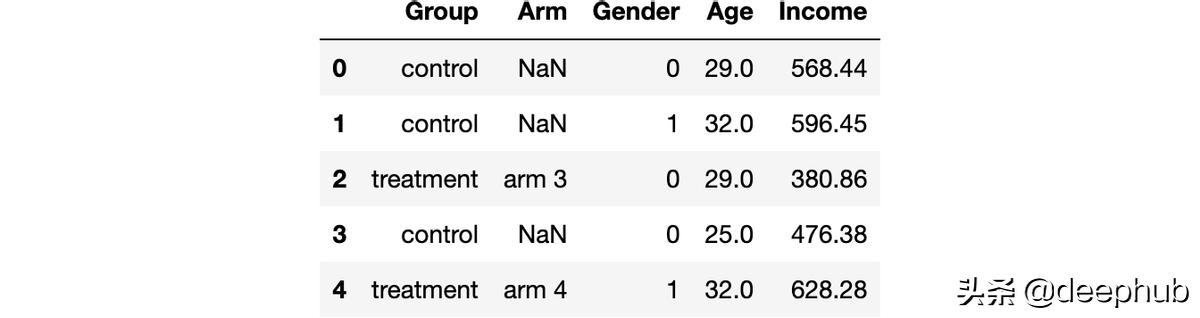

我们有1000个人的信息,观察他们的性别、年龄和周收入。每个人要么被分配到4个不同的实验组要么被分配到对照组。
2组数据对比-可视化
让我们从最简单的开始:我们想要比较整个实验组和对照组的收入分配。我们首先探索可视化方法,然后是统计方法。第一种方法的优点是可以使用我们的直觉进行判断,第二种方法的优点是使用数字判断更加的严谨。
对于大多数可视化,这里将使用Python的seaborn库。
箱线图
第一种视觉方法是箱线图。 箱线图是汇总统计和数据可视化之间的良好折衷。 框的中心代表中位数,而边框分别代表第1(Q1)和第3四分位数(Q3)。 扩展线延伸到框外超过四分位距 (Q3 – Q1) 1.5 倍的第一个数据点。 落在扩展线之外的点是单独绘制的,通常会被认为是异常值。
因此,箱线图提供了汇总统计数据(方框和扩展线)和直接数据可视化(异常值)。
sns.boxplot(data=df, x='Group', y='Income');
plt.title("Boxplot");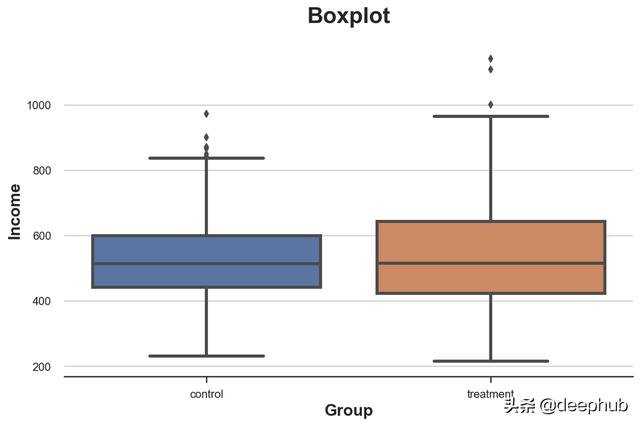
实验组的收入分配更加分散:橙色盒子更大,它的扩展线覆盖范围更广。但是箱线图的问题是它隐藏了数据的形状,它告诉我们一些汇总的统计数据,但没有显示实际的数据分布。
直方图
绘制分布图最直观的方法是直方图。直方图将数据分组到同等宽的容器(bin)中,并绘制出每个容器中的观察数据的数量。
sns.histplot(data=df, x='Income', hue='Group', bins=50);
plt.title("Histogram");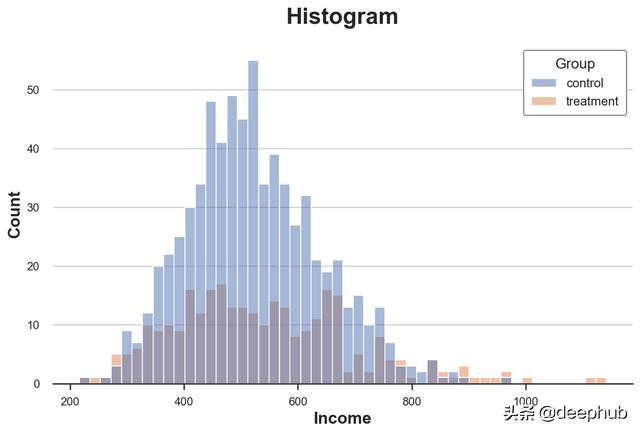
直方图也存在一些问题
- 由于两组的观察次数不同,因此两个直方图不具有可比性
- bin的数量是任意的
我们可以使用 stat 选项来绘制密度而不是计数来解决第一个问题,并将 common_norm 设置为 False 分别对每个直方图进行归一化。
sns.histplot(data=df, x='Income', hue='Group', bins=50, stat='density', common_norm=False);
plt.title("Density Histogram");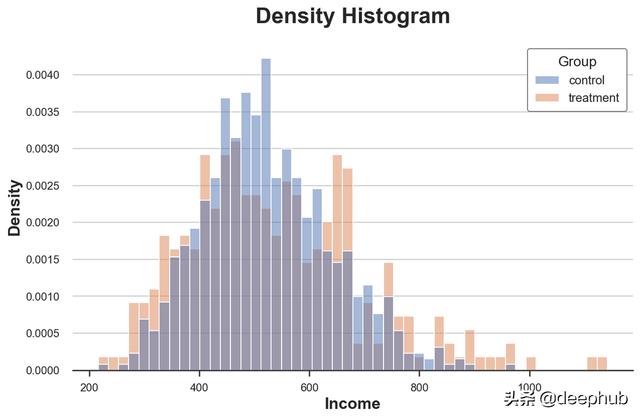
这样这两个直方图就具有可比性!
但是一个重要的问题仍然存在:bin的大小是任意的。 在极端特殊的情况下,如果我们将数据更少分组,最终会得到最多只有一个观察值的 bin,如果我们将数据分组更多,我们最终会只得到一个 bin。 在这两种情况下,我们都无法判断。 这是一个经典的偏差-方差权衡的问题。
核密度
一种可能的解决方案是使用核密度函数,该函数尝试使用核密度估计 (KDE) 用连续函数逼近直方图。
sns.kdeplot(x='Income', data=df, hue='Group', common_norm=False);
plt.title("Kernel Density Function");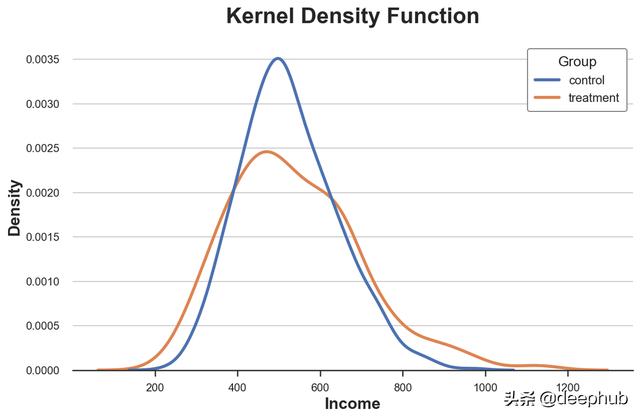
从图中可以看到,收入核密度似乎在实验组中具有更高的方差,但是各组的平均值却是相似的。核密度估计的问题在于它有点像一个黑匣子,可能会掩盖数据的相关特征。
累积分布
两种分布更透明的表示是它们的累积分布函数(Cumulative Distribution Function)。 在 x 轴(收入)的每个点,我们绘制具有相等或更低值的数据点的百分比。 累积分布函数的主要优点是
- 不需要做出任何的选择(例如bin的数量)
- 不需要执行任何近似(例如使用 KDE),图形代表所有数据点
sns.histplot(x='Income', data=df, hue='Group', bins=len(df), stat="density",
element="step", fill=False, cumulative=True, common_norm=False);
plt.title("Cumulative distribution function");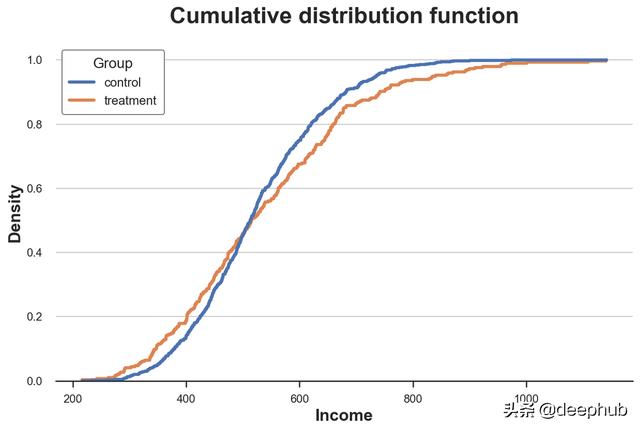
我们应该如何解释这张图?
- 由于这两条线在0.5 (y轴)处或多或少交叉,这意味着它们的中值是相似的
- 因为橙色线在左边的蓝线之上,在右边的蓝线之下,这意味着实验组的分布是fatter tails(肥尾)
QQ图
一种相关的方法是 QQ 图,其中 q 代表分位数。 QQ 图绘制了两个分布的分位数。 如果分布相同应该得到一条 45 度线。
Python 中没有原生的 QQ 图功能,而 statsmodels 包提供了 qqplot 功能,但相当麻烦。 因此,我们将手动完成。
首先,我们需要使用 percentile 函数计算两组的四分位数。
income = df['Income'].values
income_t = df.loc[df.Group=='treatment', 'Income'].values
income_c = df.loc[df.Group=='control', 'Income'].values
df_pct = pd.DataFrame()
df_pct['q_treatment'] = np.percentile(income_t, range(100))
df_pct['q_control'] = np.percentile(income_c, range(100))现在我们可以绘制两个分位数分布,加上 45 度线,代表基准完美拟合。
plt.figure(figsize=(8, 8))
plt.scatter(x='q_control', y='q_treatment', data=df_pct, label='Actual fit');
sns.lineplot(x='q_control', y='q_control', data=df_pct, color='r', label='Line of perfect fit');
plt.xlabel('Quantile of income, control group')
plt.ylabel('Quantile of income, treatment group')
plt.legend()
plt.title("QQ plot");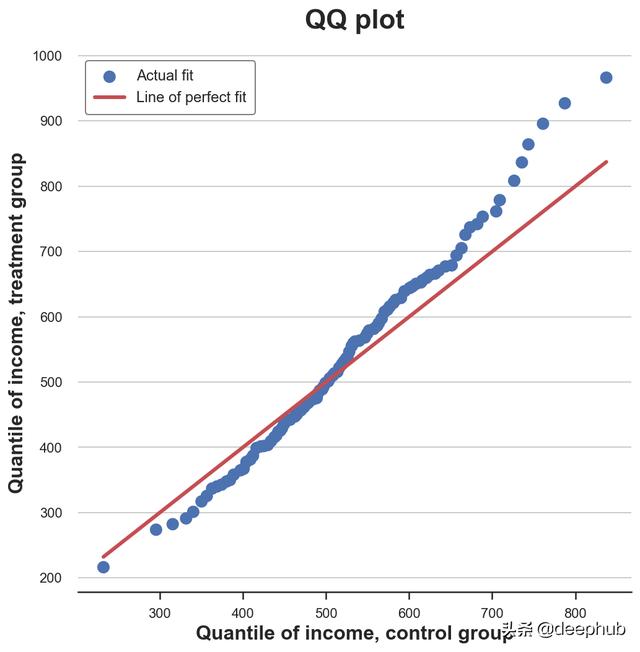
QQ 图在累积分布图方面提供了非常相似的信息:实验组的收入具有相同的中位数(线在中心交叉)但尾部更宽(点在左边的线以下,右边的线以上)。
2组数据对比-统计学方法
到目前为止,我们已经看到了不同的方法来可视化分布之间的差异。 可视化的主要优点是直观:我们可以观察差异并直观地评估它们。
然而,我们可能想要更加严格,并尝试评估分布之间差异的统计显着性,即 回答“观察到的差异是系统性的还是由于采样噪声?”的问题。
我们现在将分析不同的检验方法以区分两个分布。
T检验
第一个也是最常见的是学生 T 检验。 T 检验通常用于比较均值。 我们要检验两组的收入分配均值是否相同。 两均值比较检验的检验统计量由下式给出:
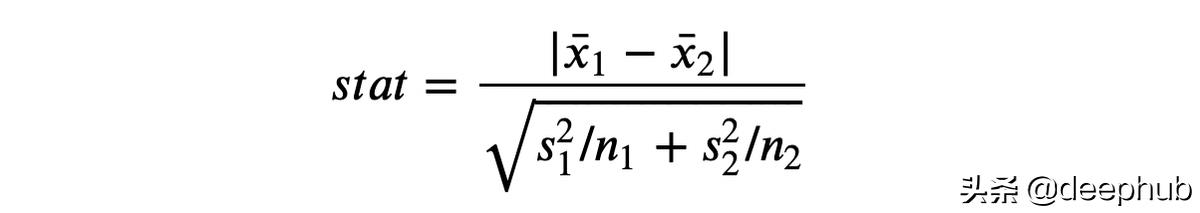
其中 x? 是样本均值,s 是样本标准差。 在较温和的条件下,检验统计量作为学生 t 分布渐近分布。
我们使用 scipy 中的 ttest_ind 函数来执行 t 检验。 该函数返回检验统计量和隐含的 p 值。
from scipy.stats import ttest_ind
stat, p_value = ttest_ind(income_c, income_t)
print(f"t-test: statistic={stat:.4f}, p-value={p_value:.4f}")
t-test: statistic=-1.5549, p-value=0.1203检验的p值为0.12,因此我们不拒绝实验组和对照组平均值无差异的零假设。
标准化平均差 (SMD)
一般来说,当我们进行随机对照试验或 A/B 测试时,最好对实验组和对照组中所有变量的均值差异进行检验。
然而,由于 t 检验统计量的分母取决于样本量,因此 t 检验的 p 值难以跨研究进行比较。 所以我们可能在一个差异非常小但样本量很大的实验中获得显着的结果,而在差异很大但样本量小的实验中我们可能会获得不显着的结果。
解决这个问题的一种解决方案是标准化平均差 (SMD)。 顾名思义,这不是一个适当的统计量,而只是一个标准化的差异,可以计算为:
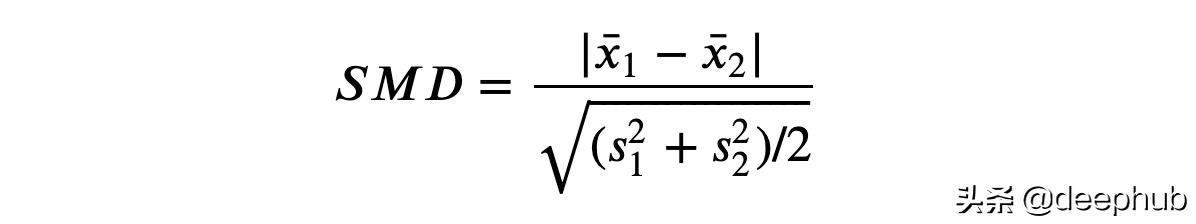
通常,低于0.1的值被认为是一个“小”的差异。
最将实验组和对照组的所有变量的平均值以及两者之间的距离度量(t 检验或 SMD)收集到一个称为平衡表的表中。可以使用causalml库中的create_table_one函数来生成它。正如该函数的名称所显示的那样,在执行A/B测试时,平衡表应该是你希望看到的的第一个表。
from causalml.match import create_table_one
df['treatment'] = df['Group']=='treatment'
create_table_one(df, 'treatment', ['Gender', 'Age', 'Income'])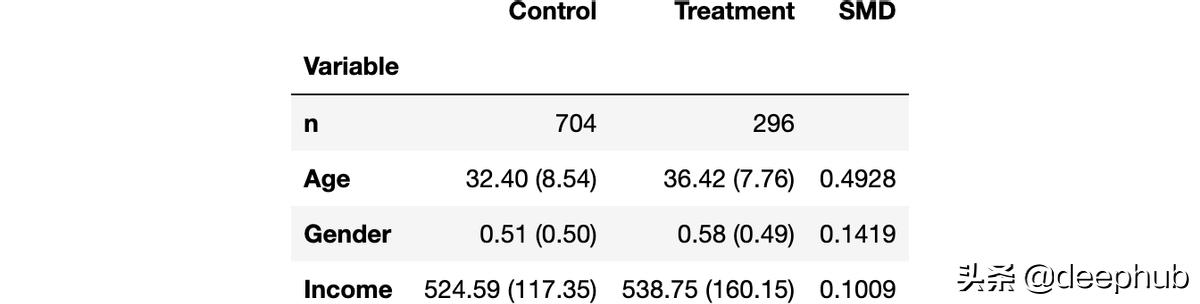
在前两列中,我们可以看到实验组和对照组的不同变量的平均值,括号中是标准误差。 在最后一列中,SMD 的值表示所有变量的标准化差异均大于 0.1,这表明两组可能不同。
Mann–Whitney U检验
另一种检验是 Mann-Whitney U 检验,它比较两个分布的中位数。该检验的原假设是两组具有相同的分布,而备择假设是一组比另一组具有更大(或更小)的值。
与上面我们看到的其他检验不同,Mann-Whitney U 检验对异常值不可知的。
检验过程如下。
- 合并所有数据点并对它们进行排名(按升序或降序排列)
- 计算 U? = R? – n?(n? + 1)/2,其中 R? 是第一组数据点的秩和,n? 是第一组数据点的数量。
- 类似地计算第二组的 U?。
- 检验统计量由 stat = min(U?, U?) 给出。
在两个分布之间没有系统等级差异的原假设下(即相同的中位数),检验统计量是渐近正态分布的,具有已知的均值和方差。
计算 R 和 U 背后的理论如下:如果第一个样本中的值都大于第二个样本中的值,则 R? = n?(n? + 1)/2 并且作为结果,U 1 将为零(可达到的最小值)。否则如果两个样本相似,U1 和 U2 将非常接近 n1 n2 / 2(可达到的最大值)。
我们使用 scipy 的 mannwhitneyu 函数。
from scipy.stats import mannwhitneyu
stat, p_value = mannwhitneyu(income_t, income_c)
print(f" Mann–Whitney U Test: statistic={stat:.4f}, p-value={p_value:.4f}")
Mann–Whitney U Test: statistic=106371.5000, p-value=0.6012我们得到的p值为0.6,这意味着我们不拒绝实验组和对照组的中位数没有差异的零假设。
置换检验
一种非参数替代方法是置换检验。 在原假设下,两个分布应该是相同的,因此打乱组标签不应该显着改变任何统计数据。
可以选择任何统计数据并检查其在原始样本中的值如何与其在组标签排列中的分布进行比较。 例如使用实验组和对照组之间样本均值的差异作为检验统计。
sample_stat = np.mean(income_t) - np.mean(income_c)stats = np.zeros(1000)
for k in range(1000):
labels = np.random.permutation((df['Group'] == 'treatment').values)
stats[k] = np.mean(income[labels]) - np.mean(income[labels==False])
p_value = np.mean(stats > sample_stat)
print(f"Permutation test: p-value={p_value:.4f}")
Permutation test: p-value=0.0530置换检验得到的 p 值为 0.053,这意味着在 5% 的水平上对原假设的弱不拒绝。那么应该如何解释 p 值? 这意味着数据中均值的差异大于置换样本中均值差异的 1–0.0560 = 94.4%。
我们可以通过绘制检验统计在排列中的分布与其样本值的分布来可视化。
plt.hist(stats, label='Permutation Statistics', bins=30);
plt.axvline(x=sample_stat, c='r', ls='--', label='Sample Statistic');
plt.legend();
plt.xlabel('Income difference between treatment and control group')
plt.title('Permutation Test');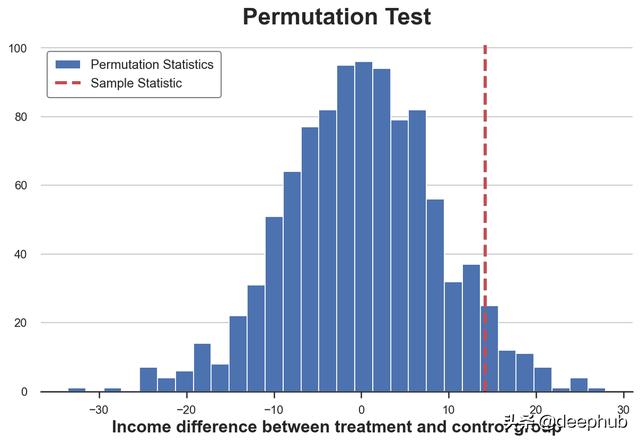
正如我们所看到的,样本统计量相对于置换样本中的值是相当极端的,但并不过分。
卡方检验
卡方检验是一种非常强大的检验,主要用于检验频率差异。
卡方检验最不为人知的应用之一是检验两个分布之间的相似性。 这个想法是对两组的观察结果进行分类。 如果两个分布相同,我们会期望每个 bin 中的观察频率相同。 这里重要的一点是需要在每个 bin 中进行足够的观察,以使检验有效。
生成与对照组中收入分布的十分位数相对应的bin,然后如果两个分布相同,我计算实验组中每个bin中的预期观察数。
# Init dataframe
df_bins = pd.DataFrame()
# Generate bins from control group
_, bins = pd.qcut(income_c, q=10, retbins=True)
df_bins['bin'] = pd.cut(income_c, bins=bins).value_counts().index
# Apply bins to both groups
df_bins['income_c_observed'] = pd.cut(income_c, bins=bins).value_counts().values
df_bins['income_t_observed'] = pd.cut(income_t, bins=bins).value_counts().values
# Compute expected frequency in the treatment group
df_bins['income_t_expected'] = df_bins['income_c_observed'] / np.sum(df_bins['income_c_observed']) * np.sum(df_bins['income_t_observed'])
df_bins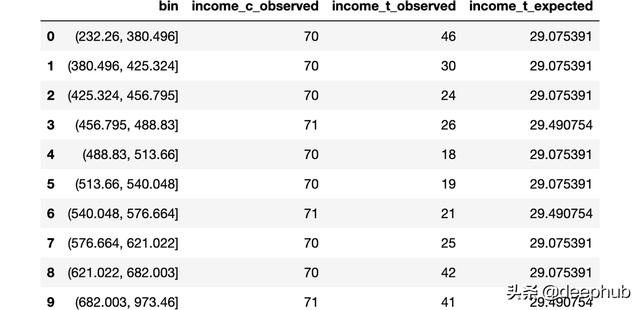
现在可以通过比较处理组中跨bin的预期 (E) 和观察 (O) 观察数来执行检验。 检验统计量由下式给出
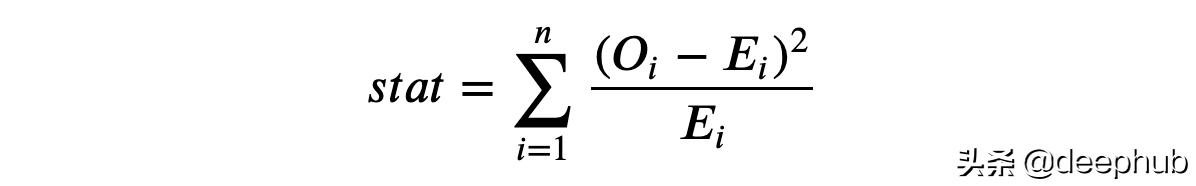
其中 bin 由 i 索引,O 是 bin i 中观察到的数据点数,E 是 bin i 中的预期的数据点数。 由于我们使用对照组中收入分布的十分位数生成了 bin,因此我们预计处理组中每个 bin 的观察数在各个 bin 之间是相同的。 检验统计量渐近分布为卡方分布。
为了计算检验统计量和检验的 p 值,我们使用 scipy 的卡方函数。
from scipy.stats import chisquare
stat, p_value = chisquare(df_bins['income_t_observed'], df_bins['income_t_expected'])
print(f"Chi-squared Test: statistic={stat:.4f}, p-value={p_value:.4f}")
Chi-squared Test: statistic=32.1432, p-value=0.0002与上面介绍的所有其他检验不同,卡方检验强烈拒绝两个分布相同的原假设。 这是为什么?
原因在于这两个分布具有相似的中心但尾部不同,并且卡方检验测试了整个分布的相似性,而不仅仅是中心,就像我们在之前的检验中所做的那样。
这个结果讲述了一个警示:在从 p 值得出盲目结论之前,了解实际检验的内容非常重要!
Kolmogorov-Smirnov 检验
Kolmogorov-Smirnov检验的思想是比较两组的累积分布。 特别是,Kolmogorov-Smirnov 检验统计量是两个累积分布之间的最大绝对差。
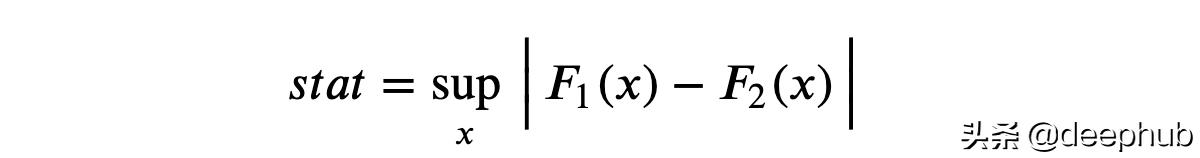
其中 F? 和 F? 是两个累积分布函数,x 是基础变量的值。 Kolmogorov-Smirnov 检验统计量的渐近分布是 Kolmogorov 分布。
为了更好地理解,让我们绘制累积分布函数和检验统计量。 首先计算累积分布函数。
df_ks = pd.DataFrame()
df_ks['Income'] = np.sort(df['Income'].unique())
df_ks['F_control'] = df_ks['Income'].apply(lambda x: np.mean(income_c<=x))
df_ks['F_treatment'] = df_ks['Income'].apply(lambda x: np.mean(income_t<=x))
df_ks.head()
现在需要找到累积分布函数之间的绝对距离最大的点。
k = np.argmax( np.abs(df_ks['F_control'] - df_ks['F_treatment']))
ks_stat = np.abs(df_ks['F_treatment'][k] - df_ks['F_control'][k])可以通过绘制两个累积分布函数和检验统计量的值来可视化检验统计量的值。
y = (df_ks['F_treatment'][k] + df_ks['F_control'][k])/2
plt.plot('Income', 'F_control', data=df_ks, label='Control')
plt.plot('Income', 'F_treatment', data=df_ks, label='Treatment')
plt.errorbar(x=df_ks['Income'][k], y=y, yerr=ks_stat/2, color='k',
capsize=5, mew=3, label=f"Test statistic: {ks_stat:.4f}")
plt.legend(loc='center right');
plt.title("Kolmogorov-Smirnov Test");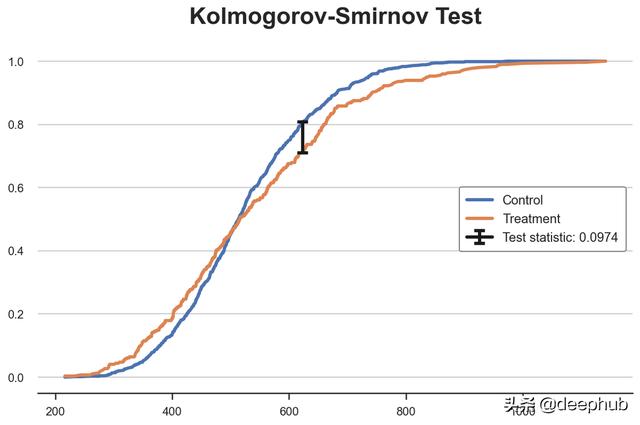
从图中我们可以看出,检验统计量的值对应于收入~650 时的两个累积分布之间的距离。 对于该收入值在两组之间存在最大的不平衡。
我们可以使用 scipy 中的 kstest 函数执行实检验。
from scipy.stats import kstest
stat, p_value = kstest(income_t, income_c)
print(f" Kolmogorov-Smirnov Test: statistic={stat:.4f}, p-value={p_value:.4f}")
Kolmogorov-Smirnov Test: statistic=0.0974, p-value=0.0355p 值低于 5%:我们以 95% 的置信度拒绝两个分布相同的原假设。
多组数据对比-可视化
到目前为止,我们只考虑了两组的情况,但是如果我们有多个组呢? 我们在上面看到的一些方法可以很好地扩展,而另一些则不能。
作为一个示例,我们现在将查看不同实验组的收入分配是否相同。
箱线图
当我们有多组时,箱线图可以很好地扩展,因为我们可以并排放置不同的框。
sns.boxplot(x='Arm', y='Income', data=df.sort_values('Arm'));
plt.title("Boxplot, multiple groups");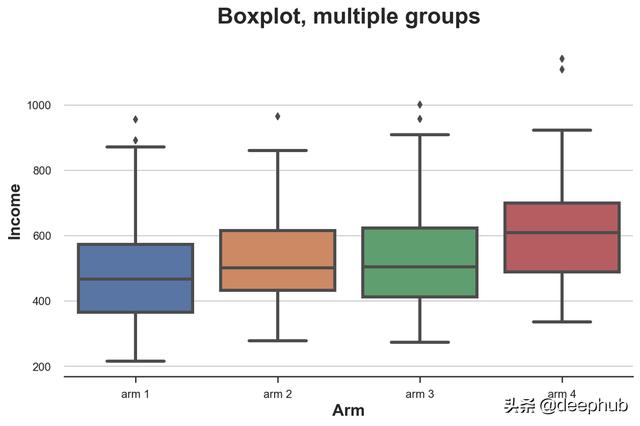
从图中可以看出,不同实验组的收入分配不同,编号越高的组平均收入越高。
提琴图
结合汇总统计和核密度估计的箱线图的一个非常好的扩展是小提琴图。 小提琴图沿 y 轴显示不同的密度,因此它们不会重叠。 默认情况下,它还在里面添加了一个微型箱线图。
sns.violinplot(x='Arm', y='Income', data=df.sort_values('Arm'));
plt.title("Violin Plot, multiple groups");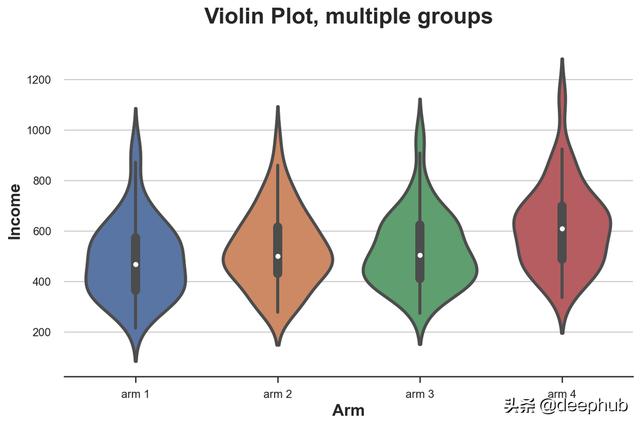
小提琴图表明不同实验组的收入不同。
山脊图
山脊图沿 x 轴绘制了多个核密度分布,它比小提琴图更直观。 在 matplotlib 和 seaborn 中都没有默认的山脊线图。 素以需要joypy包。
from joypy import joyplot
joyplot(df, by='Arm', column='Income', colormap=sns.color_palette("crest", as_cmap=True));
plt.xlabel('Income');
plt.title("Ridgeline Plot, multiple groups");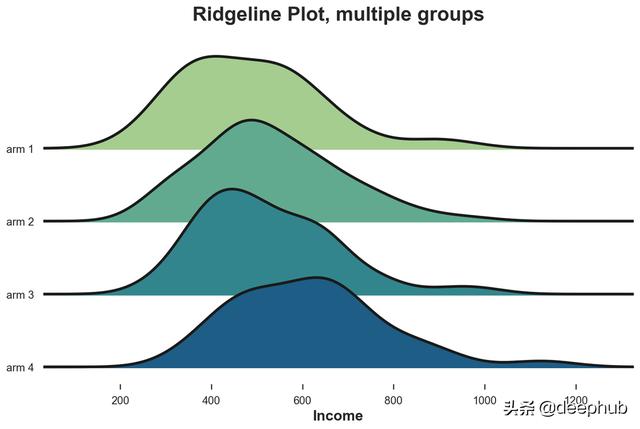
山脊图表明,编号越高的实验组收入越高。从这个图中也更容易理解分布的不同形状。
多组数据对比-统计学方法
最后,让我们考虑比较多个组的假设检验。为了简单起见,我们将集中讨论最常用的一个:f检验。
F检验
对于多个组最流行的检验方法是 F 检验。 F 检验比较不同组间变量的方差。 这种分析也称为方差分析。
F 检验统计量由下式给出
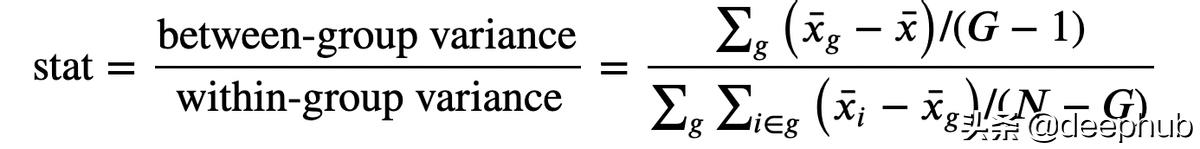
其中 G 是组数,N 是观察数,x? 是总体平均值,x?g 是组 g 内的平均值。 在组独立性的原假设下,f 统计量是 F 分布的。
from scipy.stats import f_oneway
income_groups = [df.loc[df['Arm']==arm, 'Income'].values for arm in df['Arm'].dropna().unique()]
stat, p_value = f_oneway(*income_groups)
print(f"F Test: statistic={stat:.4f}, p-value={p_value:.4f}")
F Test: statistic=9.0911, p-value=0.0000检验 p 值基本上为零,这意味着强烈拒绝实验组之间收入分配没有差异的原假设。
总结
在这篇文章中,我们看到了很多不同的方法来比较两个或多个分布,无论是在可视化上还是在统计上。 这是许多应用程序中的主要问题,尤其是在因果推断中,我们需要使随机化使实验组和对照组尽可能具有可比性。
我们还看到了不同的方法如何适用于不同的情况。 视觉方法非常直观,但统计方法对于决策至关重要,因为我们需要能够评估差异的幅度和统计意义。
作者:Matteo Courthoud

如若转载,请注明出处:https://www.shangmengchina.com/18671.html
相关推荐
-
湖南住建智慧云平台官网下载(湖南住建智慧云平台官网监理在哪个窗口)
红网时刻新闻记者 卢欣 通讯员 刘奕楠 陈淦璋 周娟 长沙报道 今年3月,“全省工程建设项目审批制度改革2.0版”打造完成,其中的深化多图联审、推行分阶段办理施工许可等专项改革,成…
-
企业在创业阶段的法律问题包括哪些,企业在创业阶段的法律问题包括哪些方面?
转行当律师后,接触到好多朋友都在创业,和创业的朋友在一起总会学到很多东西,也遇到一些朋友在创业中遇到的法律问题,我把这些案例、法律问题梳理了一下,希望朋友们未雨绸缪,避免踩坑。 1…
-
网络推广话术,怎样引导别人(网络推广话术技巧)
很多人对网站推广做词有一定的误解,或者说不知道做什么词好,这里给大家普及下做什么词,适用于各公司,请务必仔细阅读。 优化词大类只有三类词,分别是:词库词,流量词以及凑数词。 传统分…
-
项目管理w项目管理wbs案例作业s案例超市(项目管理wbs案例作业)
试题一: 阅读下列说明,回答问题1至问题3,将解答填入答题纸的对应栏内。 【说明】 某企业食堂有多个档口供员工选择餐食,员工使用现金进行支付。为了更方便员工就餐,现需要将食堂进行升…
-
qq被挡访客怎么免费查看,怎么样免费查看qq被挡访客?
昨天夜里,咱们的城市下雨了,外边小雨一直稀稀拉拉的下个不停,我突然想起了你。打开记忆的门,我打开了久违的QQ空间,沿着日历的轨迹,想去看看你。 现在我很少用QQ了,可我依旧保存着我…
-
“千万别随便取淘宝名字!!”哈哈哈哈哈哈太社死了救命
做任何事情前都要三思 哪怕是取昵称这种小事 不然你永远不知道 昵称能让你多尴尬 快来看看今天有哪些沙雕鉴赏内容吧!可能会让你笑又能消除一天的疲劳。 1. 两个人去海边游泳,其中一个…
-
炒黄金真的能赚钱吗,黄金投资真相?
相对于其他投资产品,黄金投资并不算难,因为它的投资对象单一,只需要关注金价的变化即可。但是,这并不意味着贸然进入黄金市场就能获得收益。对于普通人来说,要想在黄金市场赚到钱,需要一些…
-
抖音商品橱窗怎么开通,抖音商品橱窗怎么开通需要什么条件?
随着移动互联网的发展,越来越多的消费者开始通过手机线上购物,而抖音作为一款短视频社交平台,也开始逐步向电商方向发展。作为商家,如何在抖音平台上展示自己的商品,提升曝光度,吸引更多潜…
-
b站和抖音的区别在于,b站和抖音的区别在于什么?
诞生于2009年的B站,经历了三次重要转折,而如今正在经历着另一大转折——社区产品的商业化。B站能成功跨过这道分水岭,走出一条属于自己的商业路径,开创全新的社区商业时代吗?本文作者…
-
抖音怎么设置禁止别人保存,抖音设置不让保存?
在数字化时代,隐私保护变得尤为关键和重要。为了确保我们的个人隐私信息不会被泄露,在大数据环境中,每个软件都应当具备隐私保护功能。只需仔细设置软件隐私选项,便能实现信息保护。 在抖音…